AI: Dedicated Inference is Now Generally Available
June 15, 2026
NewAIInference
Dedicated Inference is now generally available.
Deploy AI models on dedicated NVIDIA GPUs through managed inference endpoints hosted in European data centers, without managing Kubernetes clusters, inference frameworks, or supporting infrastructure.
With this release:
- Dedicated Inference is covered by a 99.95% SLA.
- Documentation has been expanded with deployment scaling guidance, updated CLI references, service boundaries, and model compatibility requirements.
- Support and operational processes are now part of the standard Exoscale service lifecycle.
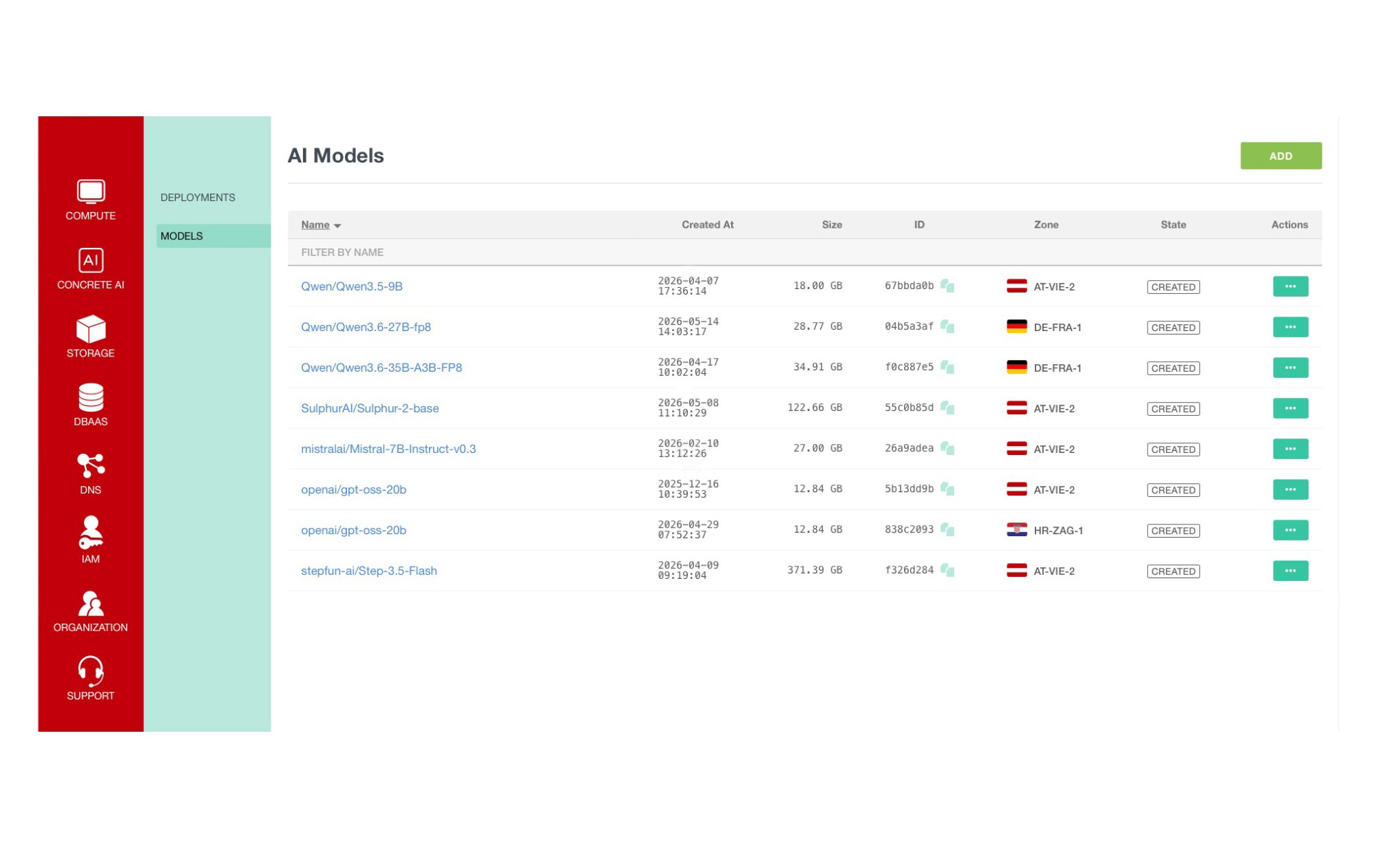
Dedicated Inference is designed for production AI workloads, including LLMs, embeddings, RAG applications, AI agents, and custom inference APIs running on dedicated GPU resources.

